Ditto’s synchronization model is designed for real-time, offline-first, and peer-to-peer (P2P) data propagation. Unlike traditional client-server architectures where clients must connect to a centralized database, Ditto enables direct communication between devices, ensuring that data stays available and up-to-date even when offline. Data synchronization works the same whether the device is synchronizing with other devices in the mesh, or with the Ditto Server. Simply by subscribing to new data, Ditto ensures that data flows from elsewhere in the mesh to the subscribing device. See Accessing Data to learn how to interact with Ditto to insert, update, and delete data within the local database. The following video provides an overview of Ditto’s data synchronization capability:Documentation Index
Fetch the complete documentation index at: https://docs.ditto.live/llms.txt
Use this file to discover all available pages before exploring further.
Subscription Queries
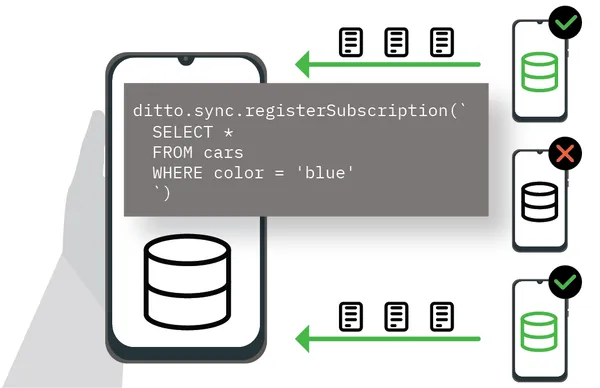
Synchronization in Ditto is event-driven. Instead of polling for changes, Ditto uses subscription queries that listen for updates and automatically receive new data in real time. With a subscription query, you can declaratively describe the data that you want a particular device to receive, whether that is all data within a collection or a filtered subset. When a query is subscribed, Ditto continuously syncs relevant documents that match the query’s criteria between all connected peers.How Subscription Queries Work
- A device adds a subscription query to listen for relevant data (see Managing Subscriptions for more detail):
- Ditto broadcasts this subscription query to all connected peers.
- When a peer has data that matches the query, whether it is an initial sync or an incremental change, it is synced to the subscribing device.
Delta Sync
Ditto synchronizes data efficiently by transmitting only the changes at the field level, rather than entire documents. This delta-based approach makes synchronization particularly efficient over bandwidth-constrained transports like Bluetooth Low Energy.How Property-Level Sync Works
When documents change, Ditto identifies which specific fields have been modified and transmits only those changes (deltas) to peers. This is achieved through:- Minimal State Transfer: Ditto calculates the minimal state needed to bring a peer up-to-date by comparing version vectors between peers
- Field-Level Granularity: For MAP data types, individual properties within a document can be updated independently, and only modified fields are synced
- On-Demand Calculation: Unlike operation-based systems that require maintaining per-peer queues, Ditto calculates diffs on-demand from local state
- Network bandwidth consumption
- Battery usage on mobile devices
- Sync latency, especially over Bluetooth LE connections
Conflict Resolution
A challenge arises in offline scenarios when two or more peers make edits independently and the data values stored by each peer diverge over time. It is necessary to perform conflict resolution to ensure that all peers ultimately reach the same value for a particular document. This conflict resolution is powered by Ditto’s use of Conflict-Free Replicated Data Types (CRDTs). Ditto adheres to the following strategies to ensure that all peers ultimately reach the same value for a particular data item:- Deterministic — As part of the strategy of eventual consistency, regardless of the order in which updates from different peers are received and merged, all peers ultimately converge to the same single value.
- Predictable and Meaningful — Instead of arbitrarily resolving conflicting
REGISTERsto a predefined value, the resulting merge accurately represents the original input and some rational interpretation of that input.
CRDTs
CRDTs are a specialized type of data structure that allow for concurrent, distributed updates to data. They are designed to be conflict-free, meaning that they can be merged together without conflict. Ditto supports the following CRDT Data Types:- Registers
- Maps
- Attachments
"123abc" on Peer A.
"A" has incorporated change from other peers "B" and "C" at times 1 and 4 respectively.
If an incoming change arrives at Peer "A" with "B": 4, then Document will merge the incoming data. This is because Peer "A" determined that the document’s current state has yet not seen the new change.
Registers
AREGISTER stores a single scalar value. You can encode the value using any JSON-compatible scalar subtype, such as a string, boolean, JSON object to represent two or more fields as a single object, and so on.
Since a REGISTER acts as a single object, to update just a single nested field of an object stored in a REGISTER, you’d need to update the entire object by providing the entire set of nested key-value pairs.
The REGISTER type adheres to the last-write-wins principle when handling concurrency conflicts. This means that when changes occur, all peers observing the change will sequence these changes in the same order. This ensures that only a consistent single value syncs across the entire peer-to-peer mesh.
For example, one flight attendant updates a customer’s seat number to 6 and another to seat 9. When the two conflicting versions merge, the edit with the latest timestamp wins.
Put another way, by enforcing the last-write-wins merge strategy, for events A and B, where B is a result of A, event A always occurs before B.
Maps
TheMAP type uses the add-wins approach to resolving concurrency conflicts.
So instead of choosing a single definitive value to merge and distribute across peers like the last-write-wins strategy utilized by the REGISTER and ATTACHMENT data types, you can choose them all — even if the data is already contained within the MAP object.
The MAP data type in Ditto forms a tree-like, parent-child relationship within a document’s dataset. This is similar to a JSON object, which functions as a single unit. However, a MAP allows:
- Nesting of various DQL data types:
REGISTER,MAP, andATTACHMENTas values for its keys. - Each key-value pair within a
MAPcan be modified independently without affecting other pairs. This property-level granularity means that when syncing, Ditto only transmits the specific fields that changed rather than the entire MAP, making sync more efficient over bandwidth-constrained transports like Bluetooth. - Utilization of an add-wins merge strategy for conflict resolution. When conflicting changes occur during sync, all conflicting changes are retained rather than converging on only one. This ensures that no data is lost when merging independent changes to the
MAP.
Attachments
TheATTACHMENT data type lets you link extensive amounts of binary data to a document for on-demand sync, both online or offline, without any conflicts. For instance, you can link and asynchronously sync large files that change infrequently or deeply embedded documents.
When incorporating an attachment into a document, rather than inserting the entire resource-heavy ATTACHMENT object, internally Ditto inserts a pointer object, known as the attachment token.
Unlike documents that are always accessible and automatically synced according to sync subscriptions, peers do not automatically fetch attachment data associated with a sync subscription. Therefore, before accessing an attachment, you must explicitly fetch it.
For practical guidance on using attachments within your application, see Working with Attachments
Causal Consistency
Causal Consistency is guaranteed by Ditto. It is causally consistent across any number of related changes, across many documents and different collections, as long as they are within the same Ditto database ID. To give an intuition about causal consistency, imagine the following scenario: On a social network Bob posts a message: Bob: “I lost my cat” Then after some time, he posts: Bob: “I found him! What a relief!” To which Sue replies: Sue: “Great news!” In contrast, an eventually consistent database shows messages in any order: Bob: “I lost my cat” Sue: “Great news!” Bob: …etc Ditto’s Causal Consistency ensures that if a new message is written after seeing some prior message, then the new message is not visible unless that prior message is also visible. To help differentiate Causal Consistency from stronger consistency models, imagine that Alice replies: Alice: “Wonderful!” Causal Consistency allows that the two concurrent messages “Great news!” from Sue and “Wonderful!” from Alice appear in any order. Both of the following results are valid with Causal Consistency: Bob: “I lost my cat” Bob: “I found him! What a relief!” Sue: “Great news!” Alice: “Wonderful!” And: Bob: “I lost my cat” Bob: “I found him! What a relief!” Alice: “Wonderful!” Sue: “Great news!”Metadata Database
Each peer individually maintains its own metadata database. The metadata database serves as a storage repository of information essential in resolving conflicts that arise when merging concurrent changes. The metadata database manages the following essential details for a particular peer:- The current state of sync.
- A record of the data previously sent and received.
- The sequence of updates.
- The timestamp of last write operation.