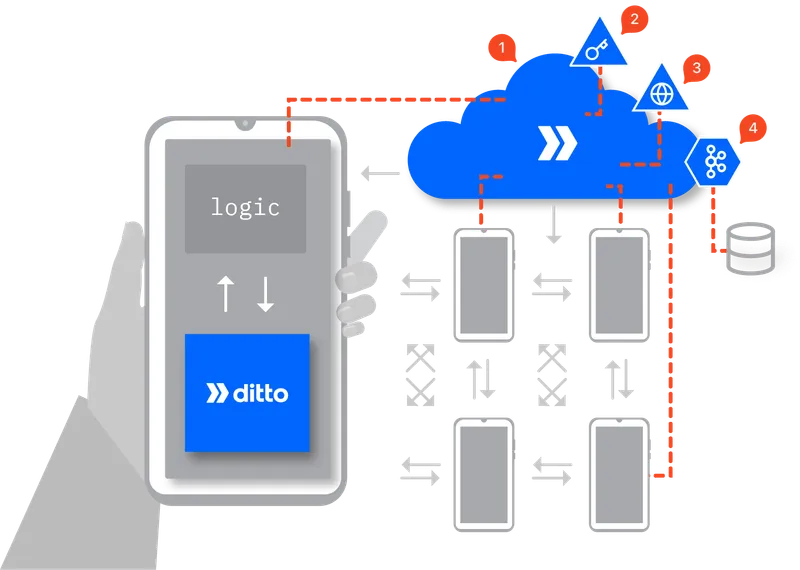
Key Services
As illustrated in the following graphic, Ditto Cloud seamlessly integrates with the Ditto Edge SDK (Small Peers), providing critical authentication services and serving as a conduit for mesh-generated data by way of the HTTP data API. Additionally, it supports third-party data integrations by offering change data capture (CDC).