- Centralized — A Small Peer device establishes a direct internet-enabled connection to Ditto Server
- Decentralized — A Small Peer device establishes a mesh network connection with nearby Small Peer devices using any and all communication transport types available to them by default.
- Hybrid — If one or multiple Small Peer devices connected in the mesh network gain access to the internet, not only do those devices with internet access upload their local Ditto store to Ditto Server, but every nearby offline Small Peer device as well.
Design Tradeoffs
Consistency Considerations
Design Tradeoffs
In distributed systems, in which a network stores data on more than one node, it is impossible to guarantee that all CAP theorem fields — consistency, availability, and partition tolerance — are met. In plain language, you can’t have it all when designing a decentralized distributed system architecture. In addition, when contending with asynchronous communications, in which unstable network conditions may cause data delays, reordering, or loss, guaranteeing partition tolerance is a must. Therefore, you must choose to sacrifice high availability or strong consistency in your architecture model. Also referred to as Brewer’s Theorem, the following graphic illustrates this CAP theorem logic: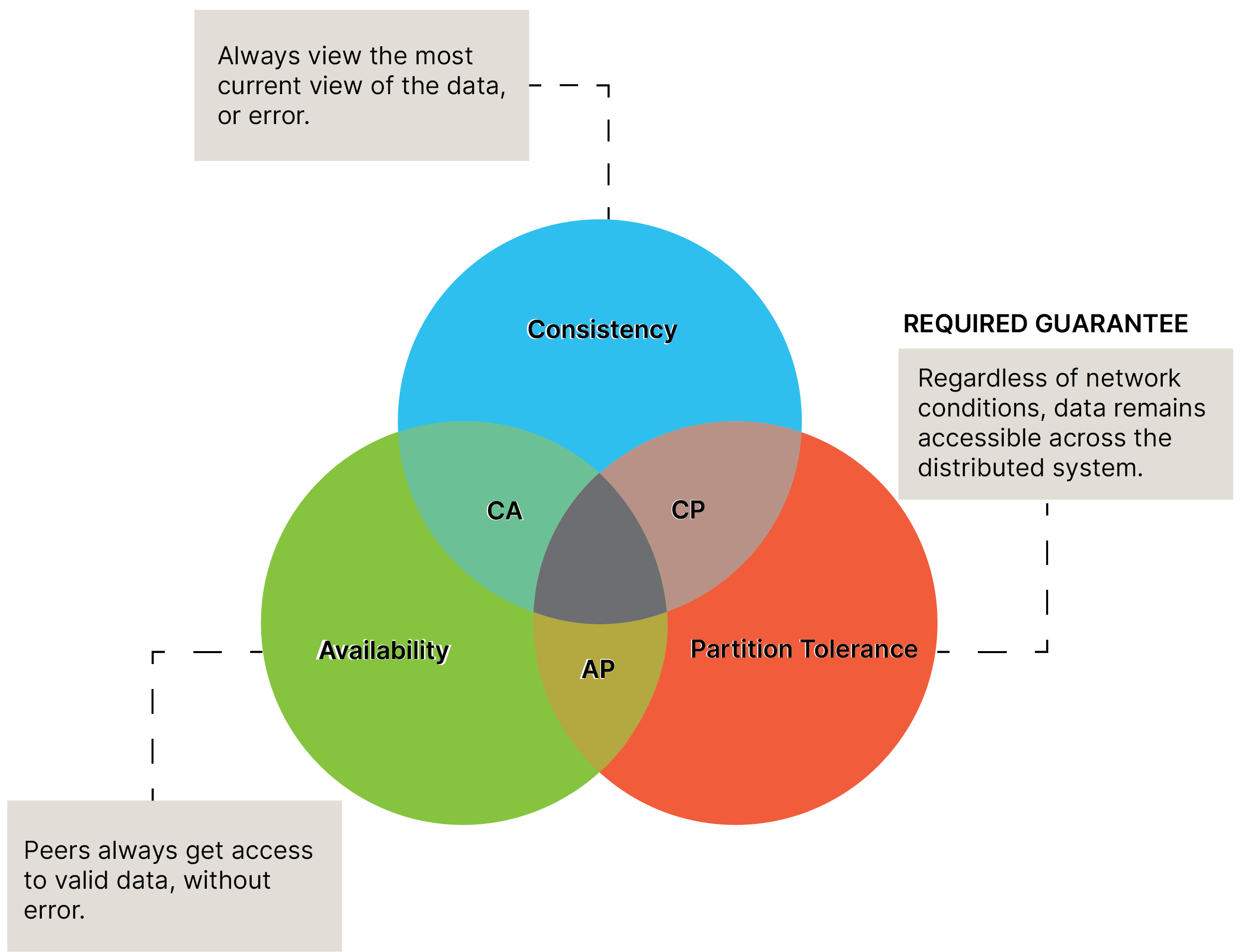
Consistency Considerations
Within Ditto’s underlying infrastructure are the following two distinct consistency models that work in tandem to achieve reliable data management. A consistency model establishes guarantees regarding the order and visibility of updates across the system. The following table provides an overview of the two types of consistency models Ditto provides:Comparing Consistency Models
When compared to the Small Peer eventually consistent model, Ditto Server causal consistency model is considered to be much more straightforward to implement in terms of ease. This is due to the causal consistency model’s relaxed approach to immediate consistency guarantees, which are susceptible to concurrency conflict.Eventually Consistent and Conflict-Free
SmallPeers enforce strong eventual consistency by way of conflict-free replicated data types (CRDTs) technology. As the foundation of how Ditto exposes and models data, CRDTs ensure that any data inconsistencies that occur as a result of concurrency conflicts eventually merge into a single value. A concurrency conflict is a simultaneous update made to the same data items stored in different database replicas. Ditto’s CRDTs are state-based, which means that only the data that has changed, known as the delta, replicates across peers in the mesh network. This paradigm ensures highly frequent and efficient peer-to-peer data transmission.Strong Causal Consistency
With the principles of eventual consistency, it seems like anything is allowed to happen: if two actions are totally unrelated, they can be ordered any way the system chooses. This is the opposite of the causally consistent model, which, as the name implies, entails that if one action occurs before another and therefore influences that other action, the two actions must be ordered in that exact same sequence for every execution. As an example, imagine that you have two collections: Menus and Orders:- First, you add a new item to the Menu, and then you create an Order that points to your new Menu item.
- When partitioned and replicated across the distributed database nodes, these two independent actions merge in a different order.
- As a result, some peers are unable to observe the new menu item referenced in the order.